

Which boosting model best predicts stock market movements?
At Affor Analytics, we strive to continuously learn from the latest research and use those insights to improve our products. That’s why we offer a bi-monthly literature review, where we dive deeper into a topic of interest. The goal is educational, with the potential to discover techniques and ideas that we can incorporate into our own solutions.
This time, we explore the question: Which boosting model predicts the stock market movements best? In recent years, there have been significant advancements in machine learning, leading to the development of several innovative models. Each new model seems to outperform the previous ones on standard machine learning benchmarks, but what we all want to know is: Which model is best suited for predicting stock market trends? And perhaps more importantly, why are certain models better for specific financial scenarios?
For this review, we analyze the performance of three leading boosting models – Adaboost, XGBoost, and LightGBM – to understand their strengths and limitations in predicting stock market movements. Boosting models have proven to be reliable for handling market data and perform better in many cases compared to more commonly known techniques like neural networks or traditional linear regression models. This is because boosting models are less prone to overfitting due to their focus on hard-to-predict instances. Additionally, boosting models require less data for training, adapt quicker to market changes, and are more robust in the presence of noise, making them particularly suited for the dynamic and chaotic nature of stock markets.
Boosting Models in market predictions
Boosting algorithms operate by iteratively improving the performance of weaker models, combining them to create a stronger predictor. This makes them especially useful for applications where even small improvements in prediction accuracy can lead to significant gains, such as financial market predictions.
Adaboost: simple and effective for small datasets
Adaboost was the first boosting algorithm to gain widespread use. It works by assigning higher weights to misclassified data points and refining the model with each iteration. Adaboost is particularly effective with smaller, simpler datasets, where it can efficiently achieve decent accuracy with few hyperparameters to tune. For example, if you are working with a small dataset of housing prices and want to predict the price of a new house based on its features, such as location, size, and number of bedrooms, Adaboost can perform well in this scenario.
However, Adaboost struggles with overfitting in more complex environments, particularly when noise or a large number of features are present. As you introduce more features, such as technical indicators or macroeconomic factors, Adaboost’s simplicity may cause it to overfit the data, reducing its effectiveness in more dynamic financial scenarios. (Freund and Schapire 1997).
XGBoost: robust and versatile for complex data
XGBoost improves on Adaboost by incorporating gradient boosting and advanced regularization techniques (L1 and L2), which help prevent overfitting. This makes XGBoost more robust when handling larger and more complex datasets.
For instance, if you’re analyzing stock prices alongside incomplete financial indicators like earnings reports, XGBoost’s ability to handle missing data makes it a powerful choice. Rather than requiring complex data cleaning, XGBoost can automatically handle these gaps, maintaining predictive accuracy. Its regularization techniques also make it more effective in managing noisy data, making it a good fit for more complex financial datasets. (Chen and Guestrin 2016).
LightGBM: fast and efficient for large-scale data
LightGBM is designed to handle large datasets efficiently, thanks to innovations like Exclusive Feature Bundling (EFB) and Gradient-Based One-Side Sampling (GOSS), which accelerate learning by focusing on the most informative data points.
This focus on speed and efficiency makes LightGBM ideal for large-scale financial applications. Its ability to rapidly process high-dimensional data allows for quicker model updates, making it particularly useful in algorithmic trading environments. However, LightGBM’s flexibility requires careful hyperparameter tuning to avoid bias, especially when dealing with unbalanced datasets. (Ke et al. 2017).
Performance breakdown in stock market prediction
When evaluating machine learning models for stock market prediction, it’s crucial to focus on the strengths and weaknesses of each model rather than focusing solely on returns. In this section, we compare the three boosting models based on several important performance metrics that highlight their predictive abilities and practical implications.
Hit ratio and Sharpe ratio: measuring accuracy and risk
At Affor Analytics, we tested Adaboost, XGBoost, and LightGBM on our financial datasets from 2000 to 2010 for training, and 2010 to 2015 for validation. Initially, with default hyperparameters, the models achieved an accuracy of 52%. After tuning the hyperparameters for each model, we observed slight improvements across the board, with accuracies increasing to 53%.
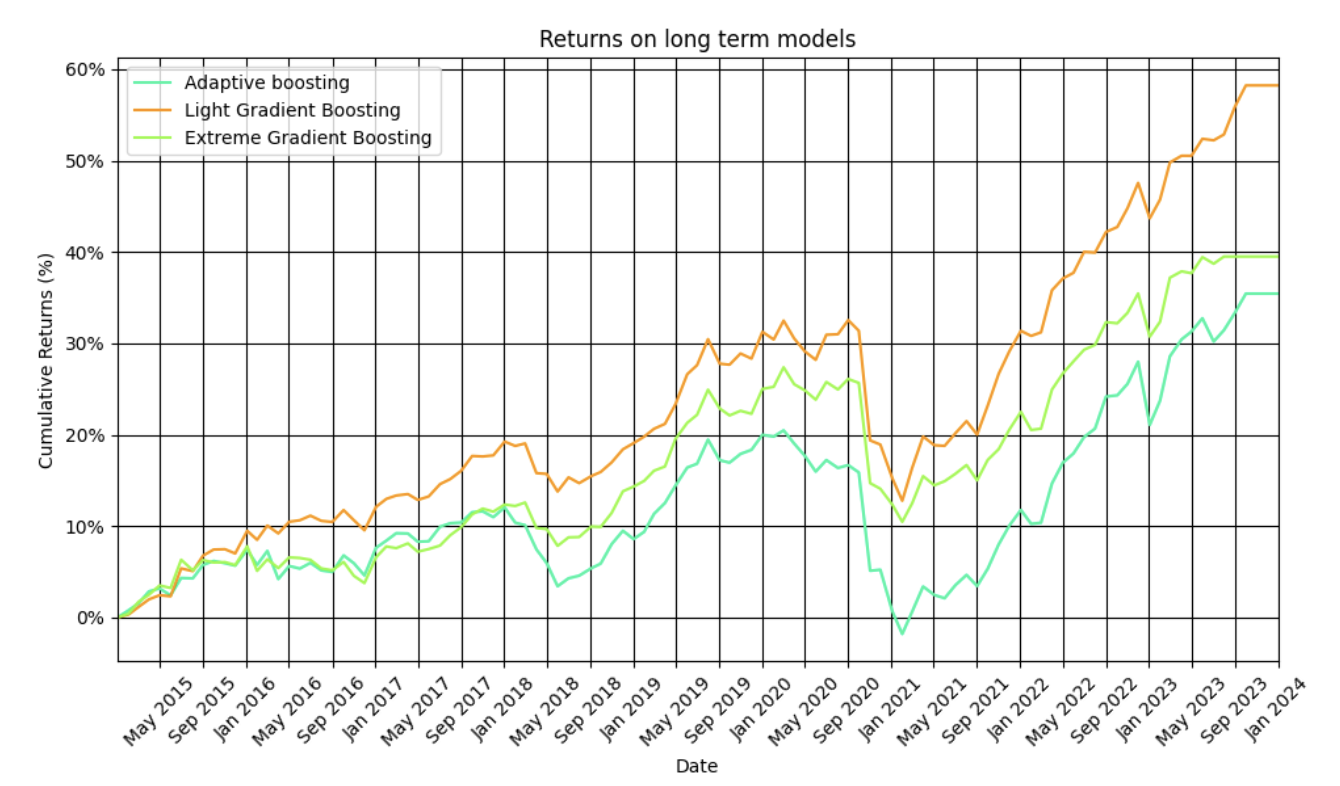
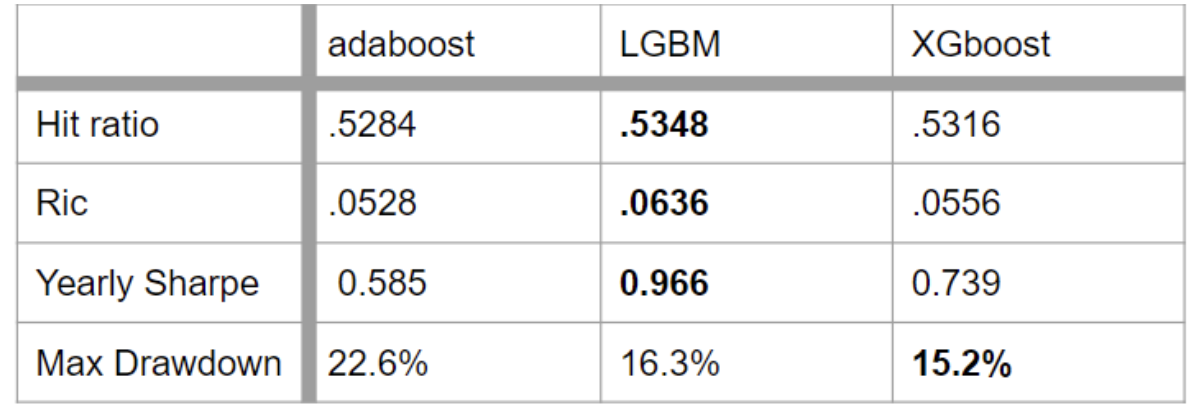
The hit ratio, which measures the percentage of correct predictions, provides a clear comparison of model accuracy. In our analysis, LightGBM achieved the highest hit ratio of 53.48%, followed closely by XGBoost at 53.16% and Adaboost at 52.84%. Although the differences in accuracy are minor, they reveal LightGBM’s slight edge in handling financial data more effectively.
The Sharpe Ratio is a more comprehensive measure that balances returns against risk, giving insight into the model’s ability to generate stable predictions in volatile market conditions. LightGBM also leads here, with a Sharpe ratio of 0.966, outperforming XGBoost (0.739) and Adaboost (0.585). This suggests that LightGBM not only makes more accurate predictions but also manages risk more effectively, which is a key consideration in financial forecasting.
Conclusion
Our analysis reveals that LightGBM outperformed the other models on our financial data, delivering the best balance of speed, accuracy, and robustness. XGBoost offered strong performance as well, particularly in handling missing data.Adaboost was effective with simpler datasets, yet it struggled with overfitting in more complex environments.
However, it’s important to remember that a machine learning model alone is not enough to guarantee strong financial performance. Data processing, cleaning, and the choice of trading strategies are equally crucial components of any successful investment approach.
Ready to harness the power of machine learning for your financial strategy? Reach out to us at Affor Analytics and see how our cutting-edge models can help you stay ahead of the market.
1. Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119-139. https://doi.org/10.1006/jcss.1997.1504
2. Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 785-794). https://doi.org/10.1145/2939672.2939785
3. Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., & Liu, T. Y. (2017). LightGBM: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems (pp. 3146-3154). https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree
Related Posts

Enhancing Equity Strategies with Affor Analytics Trading Signals
This research presents new insights how our signals can be used to enhance…

